What People Are Not Telling You Is That Cache-Augmented Generation (CAG) Is the Same as Prompt Caching

Introduction
It’s been 2 years that LLM/RAG has come mainstream and we are also started to see how it evolving as a typical software engineering workflow which would have a caching layer, design patterns and principles etc. Building solutions around LLMs are no different in various aspects. Lots of methods / researches happening around this is now mostly kind of how we can optimise the solutions we build on top of LLM. One such is Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks which we will be talking about today.
Quick Recap of Concepts
Attention Mechanism During Inference in Decoder-Only Models (Autoregressive Models):
Decoder-only models process input tokens autoregressively, attending to all previously generated tokens during each step of inference. This ensures contextual understanding but can be computationally expensive for long sequences.
Attention mechanism mathematically represented like below.
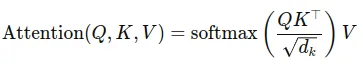
Let’s walk through an example to recall the Attention Mechanism and KV Cache.
Example Sentence
Consider a sentence: “The cat sat on the mat.”
Each word is represented as an embedding vector of dimension dₖ = 4. Here’s the embedding matrix for simplicity:
- “The” → [1,0,1,0]
- “cat” → [0,1,0,1]
- “sat” → [1,1,0,0]
- “on” → [0,0,1,1]
- “the” → [1,0,0,1]
- “mat” → [0,1,1,0]
Step 1: Creating Query (Q), Key (K), and Value (V)
The model transforms each word embedding into Query (Q), Key (K), and Value (V) vectors using learned weight matrices:
Q=Wq⋅ embedding,
K=Wₖ⋅embedding,
V=Wᵥ⋅embedding
For simplicity, let’s assume:
- Wq = Wₖ = Wᵥ = I (Identity matrix).
Thus, Q = K = V = embedding.
Step 2: Compute Similarity Scores (QKᵀ)
The dot product Q ⋅ Kᵀ measures the similarity of the Query for a token to all Keys. For the word “sat”:
Qₛₐₜ = [1,1,0,0]

Step 3: Scale and Normalize Scores
The scores are scaled by √dₖ (here √4 = 2) and passed through softmax to get attention weights:
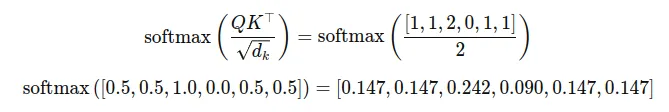
Step 4: Weighted Sum of Values
The attention weights are multiplied by the Value matrix to compute the context vector for “sat.” The Value matrix is the same as the embedding matrix in our case.
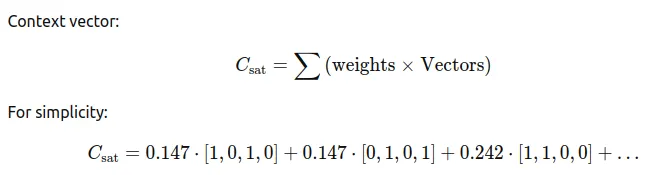
This results in a vector that represents the context of “sat” in the sentence, factoring in all words weighted by their relevance.
KV Cache During Inference in Decoder-Only Models (Autoregressive Models):
To reduce computational overhead, these models leverage Key-Value (KV) caching. This mechanism stores intermediate attention states, allowing the model to avoid recalculating attention weights for tokens it has already processed, thereby improving inference speed.
Step 1: First Token (“The”)
For the first token, no cache is available because no tokens have been processed yet.

Step 2: Second Token (“cat”)
Now, the KV cache contains K1 and V1 from the first token.

Step 3: Third Token (“sat”)
The cache now contains K1, V1 and K2V2.

The below GIF explains the concept in a much better way than text ever could. Pay special attention to the violet part, as it visually represents how the KV cache is used.
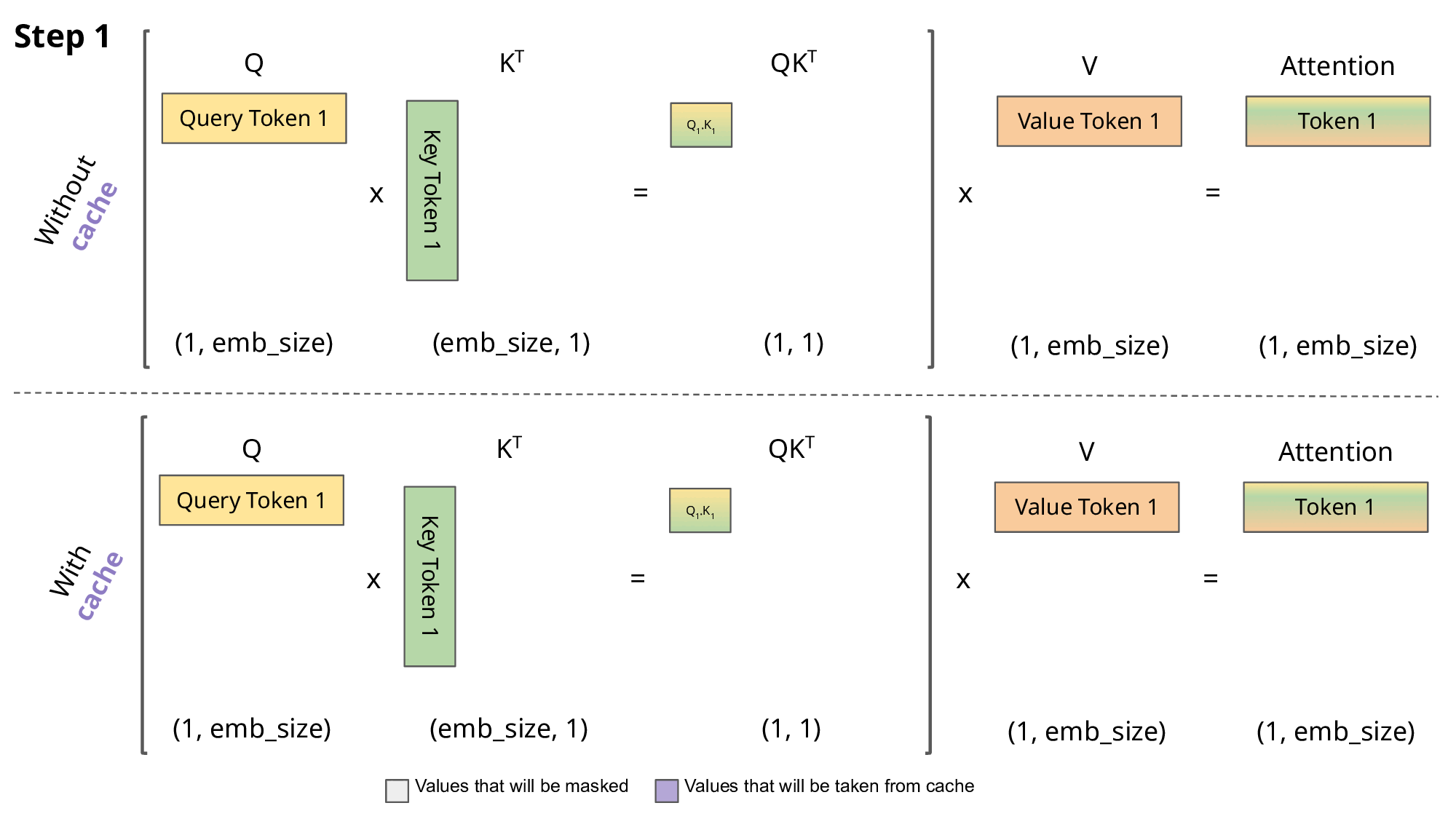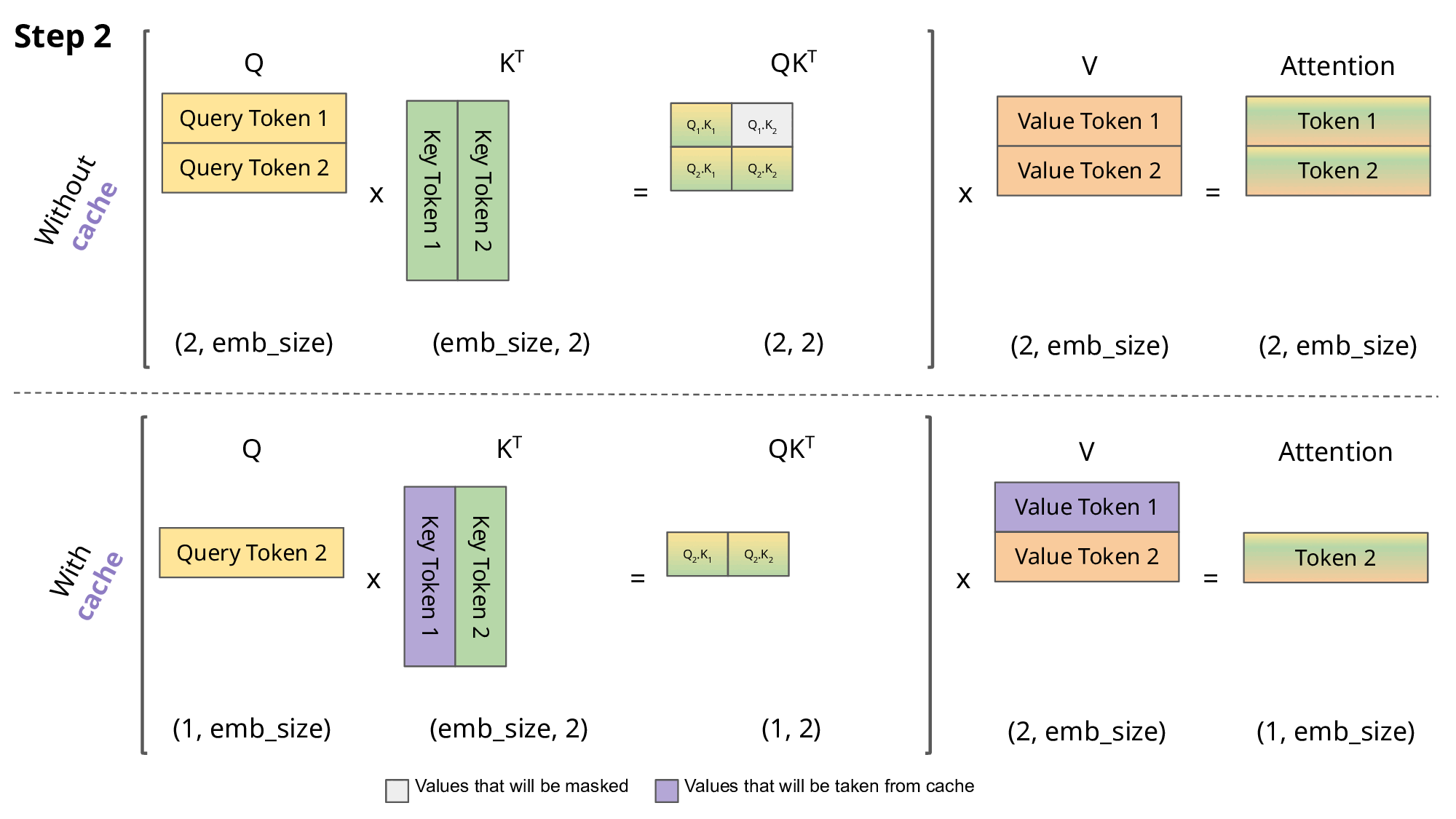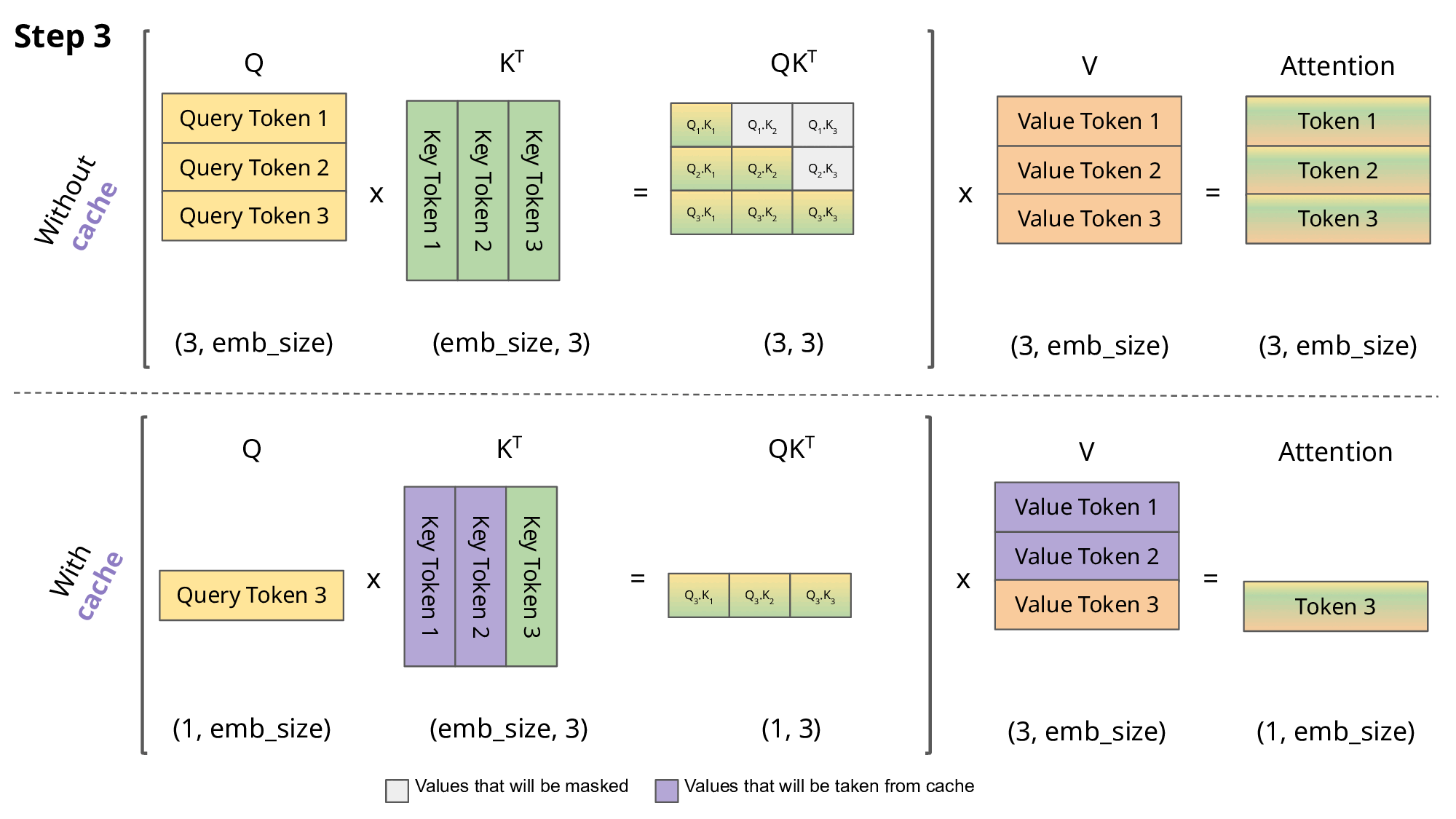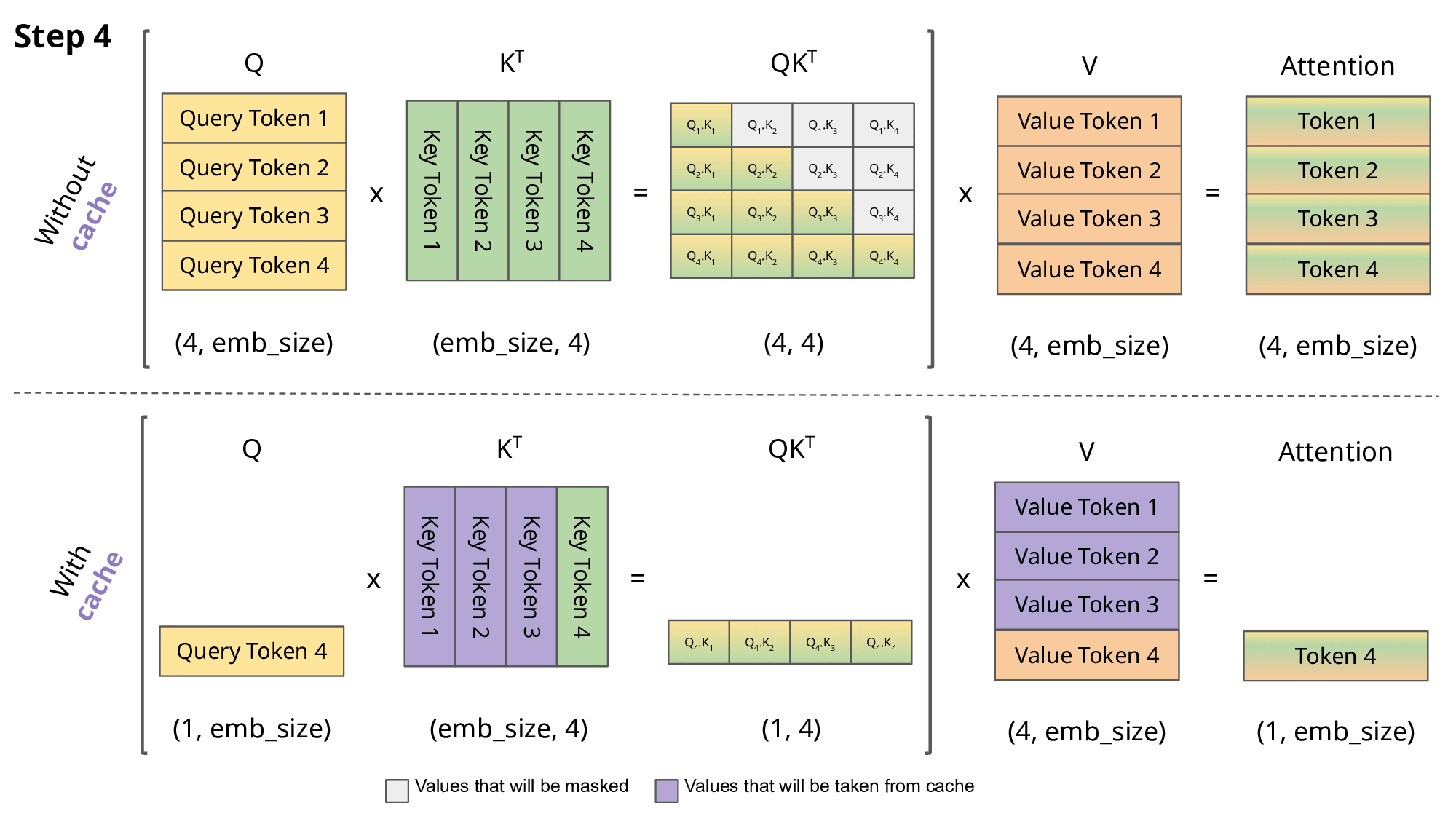
In Simple Terms
Without KV Cache: The model keeps repeating the same work for all previous words every time it processes a new one. With KV Cache: The model remembers what it already calculated and focuses only on the new word.
This makes the process faster and more efficient, especially for longer sentences.
Important: The above KV caching happens for each token within a single inference request. Now, to move into the main discussion, imagine this same caching mechanism not being limited to a single inference request but extending across multiple requests.
Prompt Caching
Prompt Caching is an optimization technique designed to improve performance when a static content = same(prompt + context) is used repeatedly in multiple API calls to LLMs. By caching this static content, subsequent API calls avoid reprocessing the same content, reducing latency and costs.
OpenAI
Prompt caching automatically activates for prompts longer than 1024 tokens — you don’t have to change anything in your completions request. When an API request is made, the system first checks if the beginning portion (prefix) of the prompt has already been cached. If a match is found (cache hit), the cached prompt is used, leading to reduced latency and costs. If there’s no match, the system processes the full prompt from scratch and caches the prefix for future use.
Model prompts often contain repetitive content, like system prompts and common instructions. OpenAI routes API requests to servers that recently processed the same prompt, making it cheaper and faster than processing a prompt from scratch. This can reduce latency by up to 80% and cost by 50% for long prompts. Prompt Caching works automatically on all your API requests (no code changes required) and has no additional fees associated with it.
Anthropic
Prompt caching is a powerful feature that optimizes your API usage by allowing resuming from specific prefixes in your prompts. This approach significantly reduces processing time and costs for repetitive tasks or prompts with consistent elements.
Note: Carefully observe that I’ve highlighted the processed word in the explanations above. This detail is very important and will play a significant role in our further discussion, so keep an eye on it.
Example: Building a Q&A Bot
Let’s say you are building a Q&A bot for a textbook. The Static Content in this case is the Prompt + Textbook Content, which remains the same for every query. Here’s how prompt caching helps:
- First Query:
- User Question: “What is photosynthesis?”
- The static content (Prompt + Textbook) is sent along with the query to the LLM.
- The system processes the static content, caches it, and answers the query.
2. Subsequent Queries:
- User Question: “What role do chloroplasts play in photosynthesis?”
- Instead of processing the static content again, the LLM loads it from the cache and only processes the new query.
- This results in faster inference and avoids redundant computation.
If we agree up to this point and share the same understanding of the concept of prompt caching, then we are on the same page and good to proceed. However, if there’s anything unclear or you feel needs correction, please feel free to point it out!
Now let’s go to our main topic CAG
CAG (Cache-Augmented Generation)
The Cache-Augmented Generation (CAG) framework leverages the ability of long-context LLMs to process large amounts of preloaded knowledge, enabling efficient, retrieval-free knowledge integration. This eliminates the challenges of traditional retrieval-augmented generation (RAG) systems, such as retrieval latency and errors. The framework operates in three key steps:
1. External Knowledge Preloading
- A collection of relevant documents D is preprocessed to fit within the model’s extended context window.
- The LLM processes this data to create a Key-Value (KV) cache:
1
Cₖᵥ = KV-Encode(D) Cₖᵥ -> KV cache
- This cache stores the model’s inference state for the documents and is saved on disk or memory.
- Cost incurred only once: Once the cache is created, it can be reused for any number of future queries.
2. Inference
- When a user query Q is received, the precomputed KV cache Cₖᵥ is loaded along with the query.
- The LLM uses the cached knowledge to generate a response: ```
1
R = LLM(Q∣Cₖᵥ) R -> Response
- This step eliminates the need for real-time retrieval of documents, reducing latency and avoiding errors.
3. Cache Reset
Skipping this in current discussion as it not relevant to our topic
With CAG, we preload all relevant documents into a long-context LLM. The model processes these documents to create a KV cache, which is saved in memory or on disk. During inference, the cache is loaded into the model, allowing efficient and retrieval-free query processing.
Important: In the same post when we discussed about KV cache we were just referring to KV cache usage within a single inference request, but here it is extended across multiple requests.
Why I Think CAG Talks About How Prompt Caching Is Implemented (Without Explicitly Saying So)
In Prompt Caching we see one most highlighted word “processed” and in CAG we see one most word “KV cache”. While prompt caching is a concept introduced by big gaints OpenAI and Anthropic which are not opensource didn’t reveal much on what exact processing they are going to reduce in other words they technically didn’t reveal what/which processing is avoided by caching, but since we have an idea that these are deocoder only model and has attention mechanism at its heart we can say one of those processing they are talking about is KV cache. So in my opinion the CAG method essentially explains how prompt caching works i.e by creating KV cache which can be reused across multiple requests.
Before we conclude, there is one technique called Semantic Caching, which is totally different. It is a very first-level cache that caches the query and LLM response, and in subsequent requests, if the question is similar, it fetches the LLM response without even calling the LLM. But in the current discussion, caching happens at the LLM. Think of it as application-side caching (Semantic Cache) and server-side caching (Prompt Cache / CAG).

Conclusion
There is no doubt that CAG is a great solution. I believe we can take it a step further by creating multiple KV caches across different sets of documents and using a lightweight classification model to select the right cache for a user query. This approach could completely avoid retrieval, even with larger document sets.
The primary reason for writing this article is that the paper didn’t mention anything about Prompt Caching, which led to some confusion. I might still be wrong in my understanding, but if CAG is indeed different from Prompt Caching, the paper could have clarified how it differs or explained why CAG is better.